This is a blog version of my slides on the topic of linear attentions. The slides were presented during the weekly group meeting/study group in our team. The storyline is highly inspired by 1.
Motivation
Attention and recurrent modules can be seen as token-mixing modules. They blend signals across the sequence domain, in contrast to FFNs or MLPs, which operate within the scope of a single token.
However, softmax attention and recurrent modules come with their own strengths and weaknesses.
| Recurrent | Softmax Attention | Linear Attention | |
|---|---|---|---|
| Training | Sequential | Parallelizable | Parallelizable? |
| Inference | Linear | Quadratic | Linear? |
| Performance | OK? | Strong | ? |
Linear attention tries to combine the best of both worlds.

Softmax Attention
- Inference:
- Each step is
- Overall complexity is when .
- Training: can be parallelized with matrix form. Causality is realized by the causal mask.
Linear Attention: Variants and Perspectives
Vanilla Linear Attention
- Bottleneck is can we remove ?
- Replace with kernel trick 3, where .
- Recent works45 discovered that a linear kernel () and no normalizer works well in practice.
- During inference:
- State is now space.
- Each token update is time.
- We have solved the quadratic complexity issue!
- What about training?
- Ideally we’d like ❌ due to .
Chunkwise Parallel Form
The chunkwise parallel form aims to balance between parallel and recurrent form. Subquadratic, partially parallel training.
-
Input is split into non-overlapping chunks with length . Number of chunks is .
-
For each chunk , calculate
can be calculated in in parallel
-
Similarly, calculate output
Training complexity is thus when .
Problems of Vanilla Linear Attention
- Performance
- Linear attention is basically
cumsum. - State/memory size is constant.
- When sequence length is long enough, the rank of would be less than , leading to key collisions.
- Linear attention is basically
- Training Efficiency
- Chunkwise parallel form is required for approximate parallel training.
RetNet2
- Motivation:
- Vanilla linear attention performs worse than softmax attention.
- Forget gates has been shown to be crucial in RNNs, but training is sequential.
- Methodology:
- Introduced a data-independent, scalar forgetting factor
- Derived both recurrent and chunkwise parallel form.

The Mamba Series67
- Started from State Space Model (SSM):
- Mamba:
- However, training cannot be parallelized.
- Mamba-2: simplified to improve training efficiency.
- Different from RetNet, is data-dependent.
GLA8
- Motivation: effectively and efficiently parametrize forgetting gate.
- RetNet: data-independent scalar.
- Mamba: data-dependent, but no parallelize training, and hardware inefficient.
- Mamba2: parallelizable training.
- Methodology:
- Forgetting gate is now column-wise instead of global.
DeltaNet9
Motivation: forgetting factor design from a fast weight programming perspective.
- Original recurrent module:
- Formulate it as a deep-learning problem:
- Model: where is the model weights.
- Training:
- Inference:
- Weight update rule: What does this mean?
- Learning rate
- maximize inner-product
💡 Any better ways to do this?
- Model:
- Loss function:
- Gradient:
- Update rule:
And there we have DeltaNet.
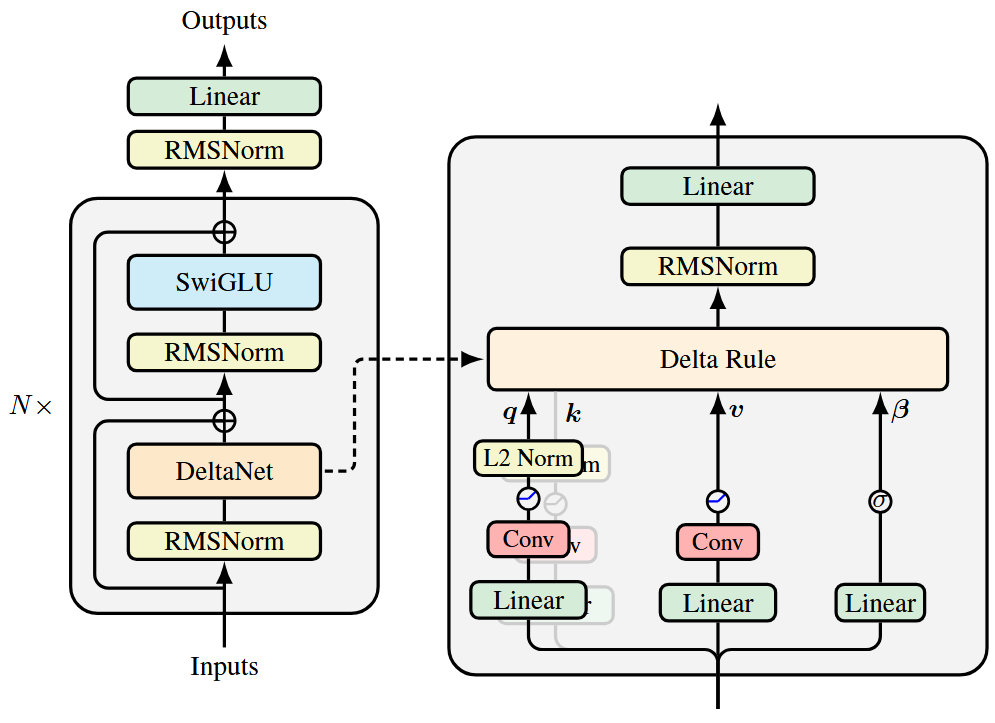
Note that the convolutions in the image are depthwise separable convolutions.
Alternative Interpretation: Key-Value Retrieval
The Delta Rule:
- Retrieves the old value using the current key .
- Obtains a new value by interpolating between the old value and the current new value , which replaces in the memory.
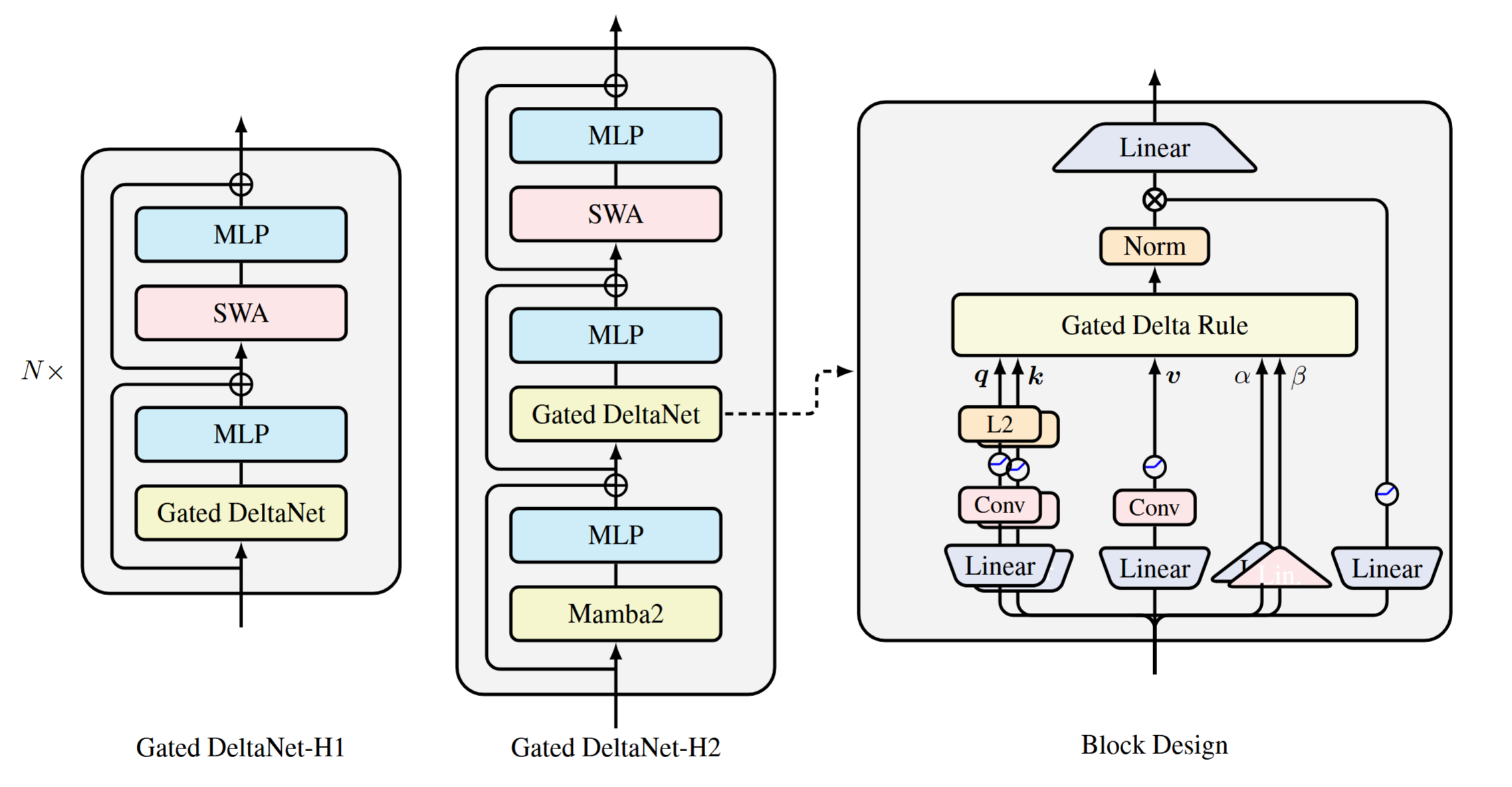
Gated DeltaNet10
- DeltaNet: precise modification of a single key-value pair.
- Adds forgetting gate from Mamba2 to allow rapid context cleanup.
- Given the update rule, the loss function can be derived as:
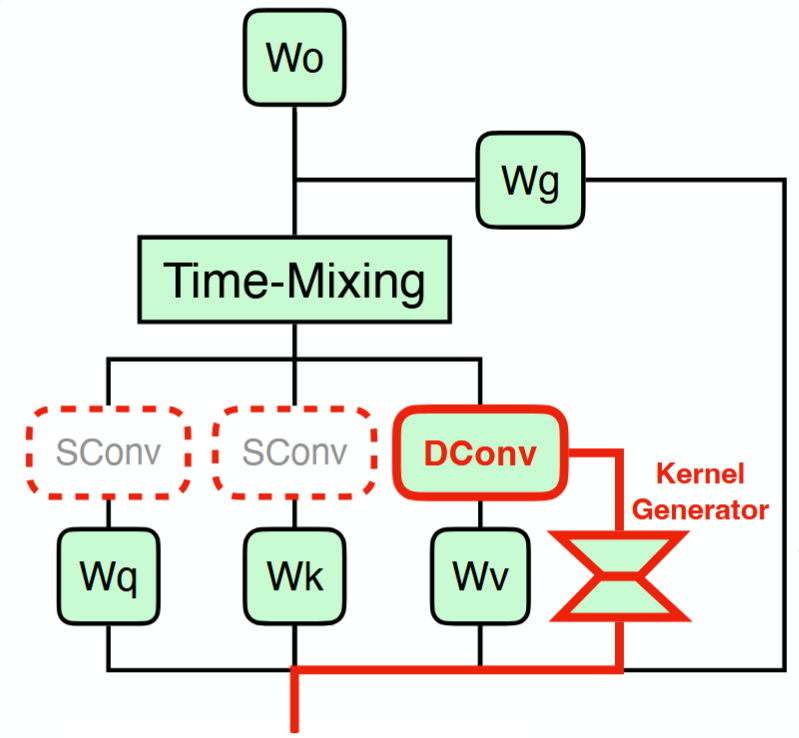
JetBlock & Jet Nemotron11
Based on Gated DeltaNet:
- Remove convolution on query and key.
- Dynamic convolution on value.
- Low-rank kernel generator with SiLU activation.
Linear Attentions in the Wild
| Model | Attention | Hybrid | Size | Date |
|---|---|---|---|---|
| MiniMax-M1 | Lightning Attention (GLA) | 7:1 | 456B (A46B) | 2025.06 |
| Qwen3-Next-80B-A3B | GDN (& Gated Attention) | 3:1 | 80B (A3B) | 2025.09 |
| IBM Granite-4.0 | Mamba-2 | 9:1 | 3B~32B (A3B) | 2025.10 |
| Kimi Linear | Kimi Delta Attention (GDN + GLA) | 3:1 | 48B (A3B) | 2025.10 |
| DeepSeek-V3.2-Exp | DeepSeek Sparse Attention | ❌ | 671B (A37B) | 2025.09 |
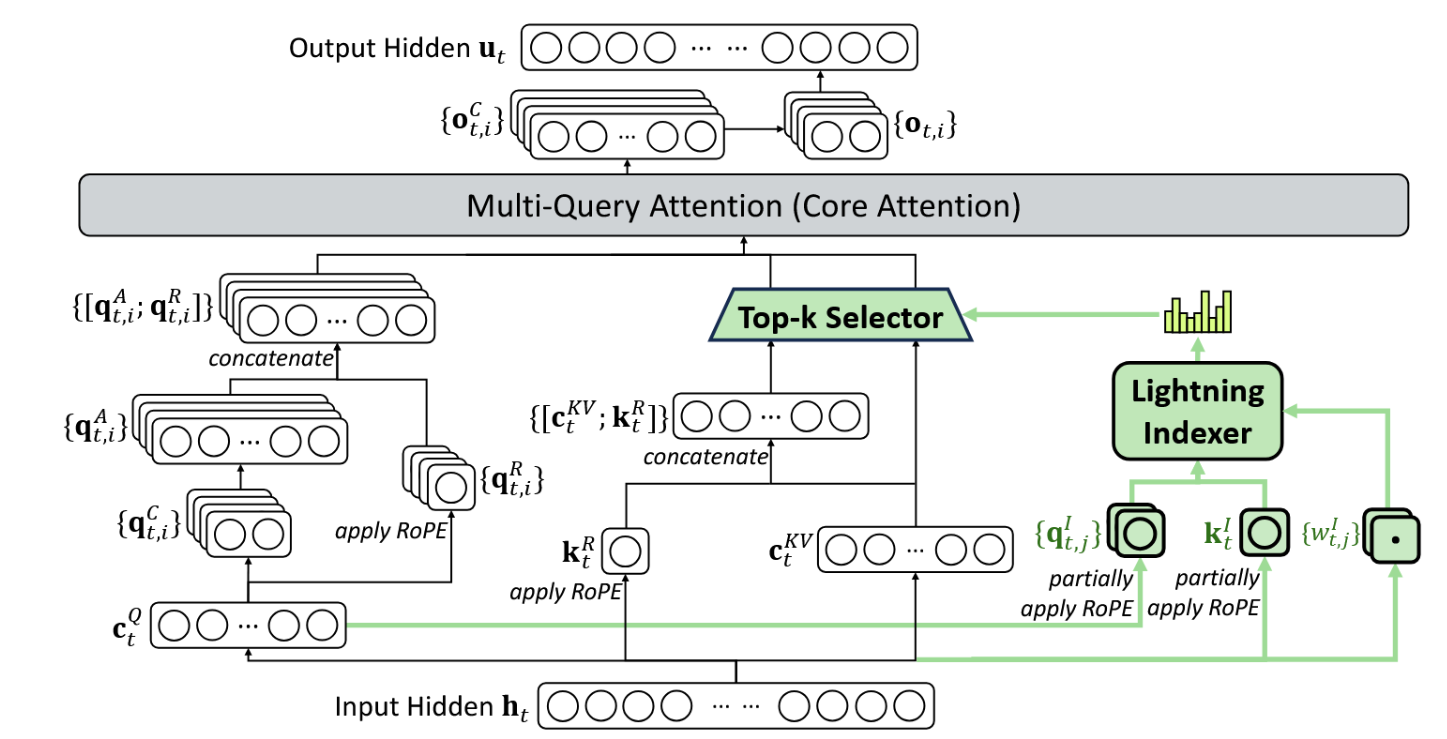
Notes on Deepseek Sparse Attention (DSA)12
- DSA is not linear attention.
- It is more like a full softmax attention with an additional top-k operator that selects only the token pairs worth attending to.
- The importance of a token pair is determined by a lightning indexer.
- Given that the index head dimension is small, the computation of the lightning indexer is small compared to the full attention. Nevertheless, the complexity of the attention part can be reduced from to , where is
index_topk. - Therefore, DSA can still be seen as subquadratic.
MiniMax-M1 vs. M213
- MiniMax-M1 utilizes GLA, while MiniMax-M2 reverts to full softmax attention.
- Full Attention still holds practical advantages across various scenarios (code/math, agents, multimodal tasks, long chain-of-thought, RL, low-precision compute, speculative decoding, etc.).
Issues
- Evaluation Difficulty
- Existing benchmarks are easy to maxed out.
- High observation cost: scaling up, more complex evaluation.
- Infrastructure Gaps for Efficient Attention
- Training: efficient attentions are often memory-bound without deep IO optimizations.
- Inference:
- Theoretical compute/memory savings only happens for long-enough sequences.
- Challenges: low-precision state storage, efficient prefix caching, speculative decoding improvements.
Conclusion & Takeaways
- Linear attention is about striking the right balance between performance and efficiency.
- Performance: gating, memory update.
- Training Efficiency: stick to chunkwise parallel form.
- Inference Efficiency: constant-size state/memory.
- Adoption is slowly increasing, but still far from mainstream.
- Infrastructure is far behind softmax attention.
Footnotes
-
苏剑林. (Jun. 20, 2025). 《线性注意力简史:从模仿、创新到反哺 》[Blog post]. Retrieved from https://kexue.fm/archives/11033 ↩
-
Sun, Yutao, et al. “Retentive network: A successor to transformer for large language models.” arXiv preprint arXiv:2307.08621 (2023). ↩ ↩2 ↩3
-
Katharopoulos, Angelos, et al. “Transformers are rnns: Fast autoregressive transformers with linear attention.” International conference on machine learning. PMLR, 2020. ↩
-
Schlag, Imanol, Kazuki Irie, and Jürgen Schmidhuber. “Linear transformers are secretly fast weight programmers.” International conference on machine learning. PMLR, 2021. ↩
-
Mao, Huanru Henry. “Fine-tuning pre-trained transformers into decaying fast weights.” arXiv preprint arXiv:2210.04243 (2022). ↩
-
Gu, Albert, and Tri Dao. “Mamba: Linear-time sequence modeling with selective state spaces.” First conference on language modeling. 2024. ↩
-
Dao, Tri, and Albert Gu. “Transformers are ssms: Generalized models and efficient algorithms through structured state space duality.” arXiv preprint arXiv:2405.21060 (2024). ↩
-
Yang, Songlin, et al. “Gated linear attention transformers with hardware-efficient training.” arXiv preprint arXiv:2312.06635 (2023). ↩
-
Yang, Songlin, et al. “Parallelizing linear transformers with the delta rule over sequence length.” Advances in neural information processing systems 37 (2024): 115491-115522. ↩
-
Yang, Songlin, Jan Kautz, and Ali Hatamizadeh. “Gated delta networks: Improving mamba2 with delta rule.” arXiv preprint arXiv:2412.06464 (2024). ↩
-
Gu, Yuxian, et al. “Jet-Nemotron: Efficient Language Model with Post Neural Architecture Search.” arXiv preprint arXiv:2508.15884 (2025). ↩
-
DeepSeekAI. “DeepSeek-V3.2-Exp: Boosting Long-Context Efficiency with DeepSeek Sparse Attention.” GitHub (2025). ↩
-
See reddit post. ↩