Summary
- Identify the optimal affine transformation for each linear layer.
- Block-wise training strategy.
- Kronecker product.
Methodology
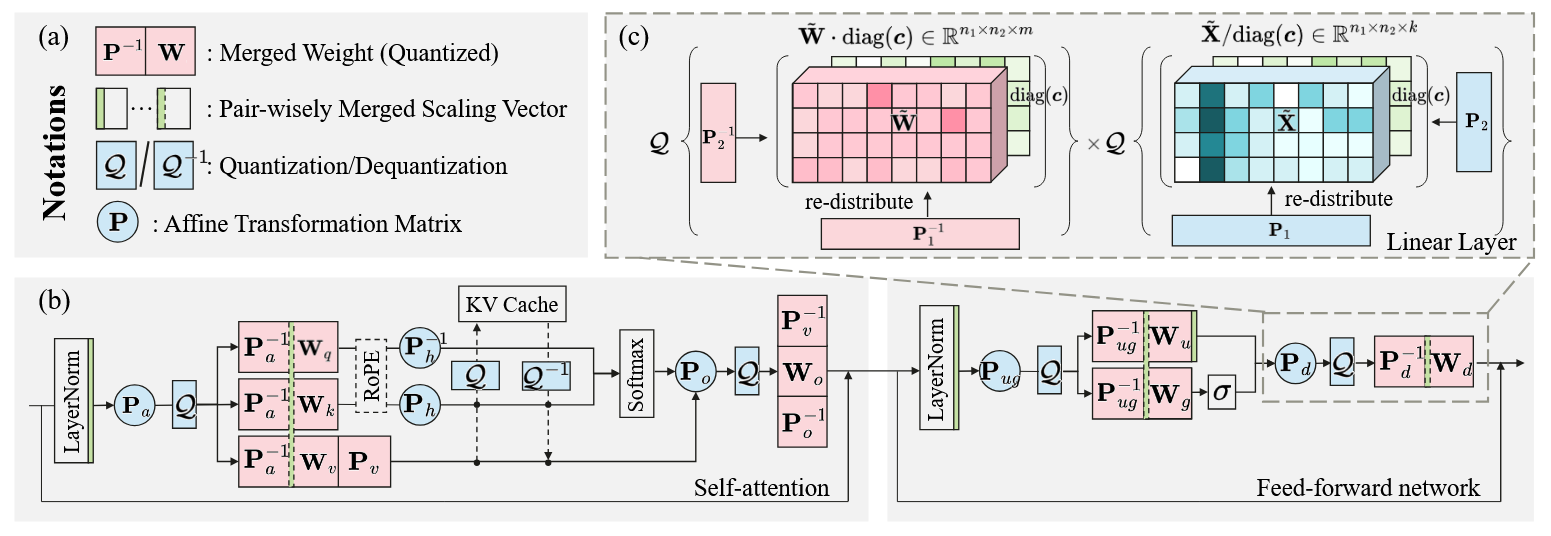
- Optimizes P∗=argminPY−Q(XP)Q(P−1W⊤)F2
- Use Kronecker product instead of full-size transformation matrix to reduce computation and memory.
- vec(V)(P1⊗P2)=vec(P1⊤VP2)
- Learnable per-channel scaling merged into weight.
- Learnable clipping thresholds ∈(0,1).
- Decoder-block-level training using MSE loss.
- Self-attention:
- Pa,Po are decomposed.
- Ph,Pv are kept in original shape due to per-head quantization already facilitates cheap transformations.
- Po,Pv are fused.
- MLP: Pug,Pd are both decomposed.