Summary
- Activation quantization!
- Use rotation to remove outliers from the hidden state without changing the output.
- Computational invariance.
- Applied to hidden states (residual), activations of feed forward components, attention mechanism, and KV cache.
- 99% accuracy retain on 4-bit quantized Llama-2-70B.
- Lossless 6 & 8-bit without any calibration data using RTN.
Methodology
Background
Hadamard Transform
-
Walsh-Hadamard matrix:
- The computation complexity of is
-
Randomized Hadamard matrix:
- is also orthogonal.
Incoherence Processing
- Introduced by QuiP.
- A weight matrix is -incoherent if
- is the element-wise max of the matrix.
- Is this different from ?
- is the element-wise max of the matrix.
- A matrix that has high incoherence is hard to quantize: the largest element is an outlier relative to the magnitude of the average element.
Computational Invariance
- No re-scaling happens in the RMSNorm block.
- In practice, re-scaling is absorbed into the adjacent weight matrices first.
Method
Inter-Block Activation
- Goal: apply incoherence processing on the activations between decoder blocks, i.e., make them easily quantizable by rotating them, .
- Merge
RMSNorminto all front linear layers (). - Choose a global randomized Hadamard transform .
- All activations between decoder blocks are rotated, therefore needed to rotate back.
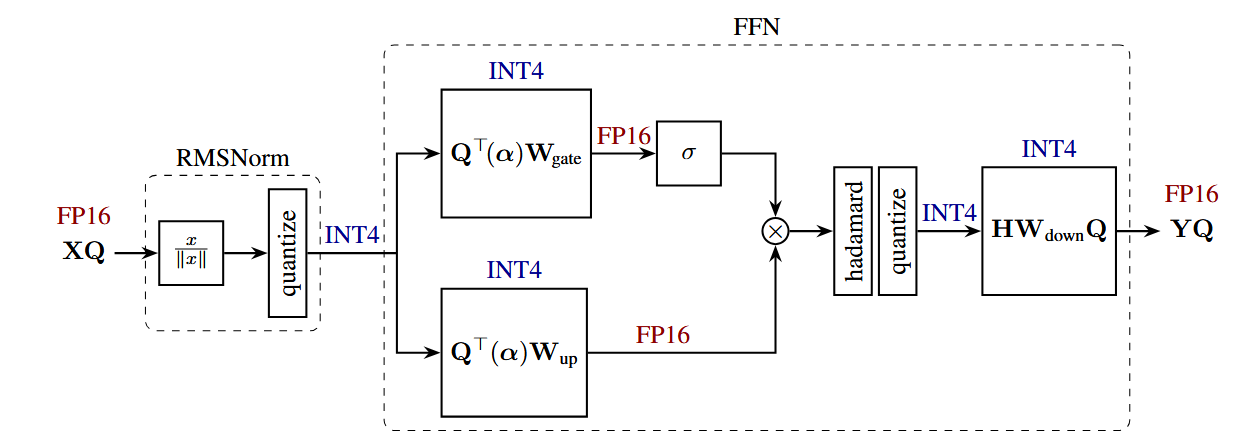
Input Activation to Down Projection
- Goal: apply incoherence processing on the input activations to
down_proj - Insert an online Hadamard transformation before .
- Merge the other half of the Hadamard transformation into
- Apply quantization to the input of
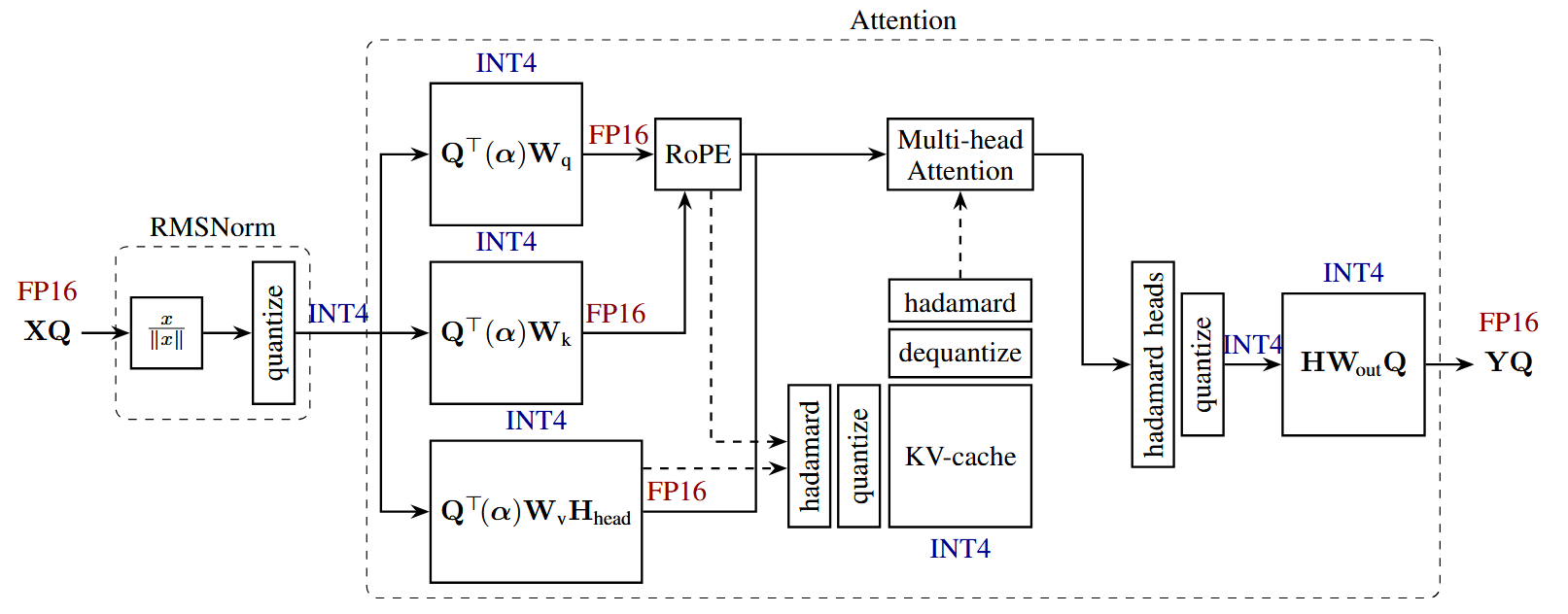
Input Activation to Out Projection
- Goal: apply incoherence processing on the input activations to
o_proj. - An additional online Hadamard (Hadamard heads) is required to head-wise rotate output of multi-head attention.
KV-Cache
- Due to positional embedding, Hadamard transformation cannot be merged into weights.
- Online Hadamard after RoPE to query and key, which would be canceled out during attention.
- Since K and V are both rotated, apply quantization and store them into KV cache.