Summary
- Introduced constant forgetting factor .
- Derived parallel and recurrent representation.
- Derived chunk-wise block-parallel form for efficient training.
Motivation
- Linear attention
- Replaces with
- Worse performance than transformers.
- Recurrent models
- Sacrifices training parallelism.
- State space models.
- Training parallelism & performance.
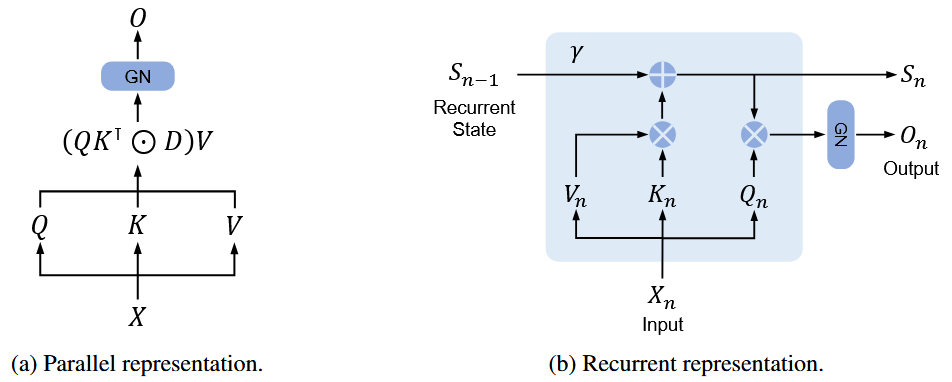
Methodology
Both recurrence and parallelism.
is diagonalized
can be absorbed into and . Therefore, the formula can be simplified as
or in recurrent form